Основы безбумажной информатики
Виктор Михайлович Глушков
Редактор О. И. Сухова. Художественный редактор Г. М. Коровина. Технический редактор С. Я. Шкляр Корректор И. Я. Кришталь.
Глава VI. Базы данных
6.1. Общие сведения
В начальный период развития ЭВМ организацией данных занимались прикладные программисты. Каждая прикладная программа снабжалась своими собственными данными, которые вводились в ЭВМ вместе с программой. Пока на ЭВМ решались отдельные, не связанные друг с другом задачи, такое положение было естественным. Однако начиная с 60-х годов и особенно в 70-е годы основная масса применений ЭВМ получила другое, так называемое системное направление.
В системных применениях задачи, решаемые на ЭВМ, взаимосвязаны в единое целое общей целью, например, управлением тем или иным сложным объектом, обработкой регулярных потоков данных и т. п. Имея дело с единым объектом, работающие в ЭВМ программы используют и формируют ту или иную систему данных об этом объекте, которую мы будем называть его информационной моделью.
На первых порах и в системных применениях преобладал позадачный подход, при котором каждая программа использовала свои данные, формируемые в изолированном от других задач процессе. При этом приходилось повторять многократный ввод и вывод по существу одних и тех же данных. Например, при управлении предприятием определенные данные о его производственном персонале используются не только в системе кадрового Учета, но и при решении задач планирования, начисления зарплаты и т. д. Естественно поэтому ввести эти данные в ЭВМ один раз, создав базу данных о кадрах предприятия и предоставив возможность любым прикладным программам черпать необходимые для них данные из этой базы.
Выгодность подобного подхода имеет несколько аспектов. Во-первых, достигаемая при этом одноразовость ввода резко уменьшает нагрузку на устройства ввода и подготовки данных, являющиеся наиболее узким местом безбумажной информатики как в части пропускной способности, так и трудоемкости. Второе преимущество заключается в достижении независимости процесса сбора и обновления или, как принято говорить, актуализации данных от процесса их использования прикладными программами.
Это позволяет в свою очередь, во-первых, разделить работу по автоматизации этих процессов между разными коллективами программистов и тем самым ускорить процесс создания соответствующих автоматизированных систем. Во-вторых, устраняется опасность ошибок из-за возможной разновременности актуализации данных в различных программах. И, наконец, в-третьих, достигается большая гибкость как в изменении и расширении состава прикладных программ, так и в отношении совершенствования организации самой базы данных.
Последнее преимущество предполагает независимость прикладных программ от физической организации базы данных. Такая независимость достигается с помощью специального (системного) программного обеспечения, которое интерпретирует так называемый язык манипулирования данными. Будучи процедурно, а не машинноориентированным, подобный язык, при использовании его в качестве дополнения к процедурно- или проблемно- ориентированным языкам программирования, позволяет писать прикладные программы, не вникая в фактическое расположение данных во внешней памяти.
Универсальные базы данных, обслуживающие любые запросы прикладных программ, вместе с соответствующим программным обеспечением принято называть банками данных. Подобно тому как обычный банк является хранилищем вкладов, банк данных может рассматриваться как хранилище информации (баз данных), принадлежащей в общем случае многим пользователям. Владельцы информации определяют правила доступа к ней других пользователей, правила ее актуализации, длительность хранения и др. Для реализации этих возможностей банк данных снабжается специальным программным обеспечением. Кроме того, функционирование банка предполагает наличие одного или нескольких человек, выполняющих функции администрации банка. Не являясь формально владельцем содержимого банка, администрация несет полную ответственность за правильность его функционирования.
6.2. Справочно-информационные системы
Первые банки данных были использованы для автоматизации справочно-информационной деятельности. Здесь понятие банка данных выступает в наиболее чистой форме ввиду фактического отсутствия прикладных программ. В автоматизированных информационных системах (АИС) их заменяет интерпретатор языка запросов, позволяющий формулировать требования к выдаче тех или иных справок. В простейшем случае такая справка представляет собой одну или несколько записей из некоторого файла (см. § 1.8).
6.2.1. Фактографические АИС
Различают фактографические АИС, у которых базы данных составляются из форматированных (формализованных) записей, и документальные АИС, записями которых могут служить различные неформализованные документы (статьи, письма и т. п.). В простейшем случае фактографическая АИС имеет в качестве базы один файл с записями фиксированного формата (все записи имеют одну и ту же длину). Примером форматированных записей могут служить, скажем, записи об операциях по приему и выдаче денег в сберкассе; запись имеет четыре основных атрибута: дата, характер операции (принято, выдано), сумма, остаток вклада.
В качестве форматированной записи может рассматриваться кадровая анкета (личный листок по учету кадров). Правда, такие ее разделы, как «прежняя работа», «поездки за границу» и др. в обычной анкете не до конца формализованы и, главное, имеют переменную длину, поэтому при автоматизации кадрового учета необходимы некоторые доделки. В частности, полная формализация раздела «прежняя работа» требует составления классификатора предприятий и организаций (причем не только в настоящем, но и в прошлом). Кроме того, обычно бывает целесообразно фиксировать максимальное количество позиций в каждом разделе и тем самым выравнивать длину записей (у многих записей при этом могут возникнуть позиции с пустым заполнением). С этими дополнениями мы будем рассматривать систему кадрового учета как базовый пример простейшей фактографической АИС.
Среди атрибутов (форматированных) записей обычно существует атрибут, который однозначно идентифицирует запись. В системе кадрового учета таким атрибутом является учетный номер работника, которому принадлежит данная запись (анкета). Подобный атрибут называется основным (или первичным) ключом. По нему определяется (с помощью специальной программы или таблицы) адрес записи во внешней памяти.
Одной из важнейших задач АИС является быстрый подбор записей, обладающих теми или иными свойствами, например — выбрать все анкеты людей данного возраста или данной профессии. Атрибуты, которыми задаются эти свойства, как правило, идентифицируют не одну запись, а некоторое множество записей. Они называются дополнительными (или вторичными) ключами.
Поиск нужных записей по дополнительному ключу обычно разбивается на два этапа. На первом этапе определяются значения основного ключа, отвечающие записям с заданным значением дополнительного ключа. На втором этапе по найденным значениям основного ключа находят адреса записей, а затем и сами записи. Для быстрого выполнения первого этапа (без последовательного просмотра всех записей) используются так называемые инвертированные списки. Каждый такой список состоит из пар значений дополнительного и соответствующего им множества значений основного ключа, упорядоченных по дополнительному ключу.
Пусть, например, первоначальный файл состоит из записей с тремя атрибутами: учетный номер, год рождения, код профессии. Возьмем для простоты лишь 12 записей (табл. 6.1).
Таблица 6.1.
| Учетный номер | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| Год рождения | 1950 | 1945 | 1950 | 1947 | 1945 | 1950 | 1951 | 1953 | 1949 | 1950 | 1957 | 1946 |
| Код профессии | 03 | 01 | 05 | 03 | 02 | 04 | 03 | 03 | 02 | 01 | 08 | 09 |
Список, инвертированный по ключу год рождения, приведен в табл. 6.2.
Таблица 6.2
| Год рож-дения | 1945 | 1946 | 1947 | 1949 | 1950 | 1951 | 1953 | 1957 |
| Учетный номер | 2, 5 | 12 | 4 | 9 | 1, 3, 6, 10 | 7 | 8 | 11 |
Список, инвертированный по ключу код профессии, приведен в табл. 6.3.
Таблица 6.3
| Код профессии | 01 | 02 | 03 | 04 | 05 | 08 | 09 |
| Учетный номер | 2, 10 | 5, 9 | 1, 4, 7, 8 | 6 | 3 | 11 | 12 |
Объединение инвертированных списков по всем дополнительным ключам составляет так называемый (полностью) инвертированный файл. Имея такой файл, легко найти записи с данными атрибутами. Например, в нашем случае профессию с кодом 03 и одновременно год рождения 1950 имеет лишь работник с учетным номером 1. Если инвертированные списки не перекрывают все множество ключей, то говорят о частично инвертированном файле.
6.2.2. Документальные АИС
Основной задачей, решаемой в документальных АИС, является поиск документов по их содержанию. Если язык запросов (как и язык самих документов) является обычным (неформализованным) человеческим языком (возможно, с тем или иным профессиональным уклоном), то полное решение задачи поиска требует понимания системой смысла запросов. Такая задача тесно связана с проблемой создания так называемого искусственного интеллекта и на сегодняшний день еще достаточно далека от полного решения.
Поэтому в практике документальных АИС употребляются упрощенные способы поиска. Простейшим из них является использование так называемых дескрипторов, под которыми понимается некоторое фиксированное множество слов (в том числе специальных профессиональных терминов), которые, по мнению разработчика данной конкретной АИС, в наибольшей степени характеризуют содержание ее документального фонда. Например, если фонд составляют статьи по медицине, то в качестве дескрипторов естественно использовать названия болезней, лекарств и лечебных процедур, а также такие термины, как лечение, диагностика и др.
Наиболее прямолинейное решение задачи поиска при использовании фиксированного словаря дескрипторов заключается в следующем: АИС просматривает текст запроса (на обычном, неформализованном языке) и фиксирует все встречающиеся в тексте дескрипторы. Например, в запросе «найти все статьи по диагностике рака» выделяются дескрипторы «диагностика» и «рак». После этого система просматривает полные тексты всех документов (статей) и отбирает из них те, которые содержат оба выделенных дескриптора.
При реализации подобной процедуры нужно дополнительно учесть то обстоятельство, что как в тексте запроса, так и в тексте документа дескрипторы могут трансформироваться (и притом по-разному) в соответствии с требованиями грамматики используемого языка. В приведенном примере дескриптор «рак» встречается в родительном падеже с окончанием «а», а в тексте статьи он может встретиться в других падежах. Поэтому идентификация дескрипторов должна проводиться с точностью до окончаний (а иногда и до суффиксов).
Следует иметь в виду также и то, что просмотр полных текстов документов требует много времени. Требования повышения производительности АИС заставляют вместо просмотра самих документов просматривать их поисковые образы. В качестве таковых в простейшем случае выступают просто перечни встречающихся в документах дескрипторов. Поисковые образы составляются заранее либо вручную, либо автоматически (в результате одноразового просмотра текстов специальной программой). Обычно эти образы хранятся отдельно от текстов самих документов, имея в своем составе ссылку на адрес соответствующего документа. Аналогичным образом для запроса составляется поисковый образ запроса. В процессе поиска происходит сравнение поисковых образов документа и запроса на основе критерия смыслового соответствия, фиксированного для системы, либо указываемого при формулировке запроса. При этом документ считается релевантным запросу, если условие сравнения выполняется. В качестве критерия смыслового соответствия может выступать, например, условие совпадения множеств дескрипторов поисковых образов документа и запроса, включение множеств друг в друга, их пересечение и др. Поскольку наиболее дешевым способом хранения информации являются сегодня микрофиши, то для хранения полных текстов документов используют обычно их. В памяти же ЭВМ (внешней) хранятся лишь поисковые образы документов.
Специальные устройства автоматического поиска и копирования в библиотеке микрофишей позволяют после нахождения адреса документа в считанные секунды получить его так называемую твердую копию. Такая копия представляет собой обычный бумажный документ со шрифтом нормального (ориентированного на человека) размера.
Заметим, что документальная АИС с простыми дескрипторными поисковыми образами может рассматриваться как фактографическая система с булевыми (да — нет) атрибутами, число которых равно полному числу используемых дескрипторов. Однако такое представление является экономичным лишь при относительно небольшом числе дескрипторов.
Несовершенство описания содержания простой системой дескрипторов заключается прежде всего в том, что в обычных языках имеется много средств для выражения одного и того же смысла. В результате может оказаться, например, что в статье по диагностике той или иной болезни само слово «диагностика» не будет встречаться ни разу. Наоборот, наличие в тексте статьи термина «диагностика» еще не означает, что статья посвящена именно диагностике. Это может быть всего-навсего случайная ремарка. Поэтому при поиске по дескрипторам могут быть извлечены так называемые нерелевантные документы, т. е. не имеющие отношения к рассматриваемому запросу, и, наоборот, некоторые релевантные документы могут оказаться не найденными. В первом случае говорят о неточности (информационном шуме) рассматриваемой АИС, во втором — о ее неполноте.
Применительно к каждому конкретному запросу определяются (экспертным путем) два коэффициента. Коэффициент полноты представляет собой отношение числа выданных по запросу релевантных документов к их общему числу в поисковом массиве. Коэффициент точности есть отношение релевантных (в данной выдаче) документов к общему числу выданных (релевантных и нерелевантных) документов. Для многих запросов система может характеризоваться как средними значениями этих коэффициентов, так и их минимальными (наихудшими) значениями.
Несовершенство простого язы ка дескрипторов проявляется также и в том, что на нем в принципе не могут быть выражены некоторые важные нюансы смысла. Например, наличие в документе дескриптора «поставка» и дескрипторов — имен А и В поставщика и потребителя ничего не говорит о том, кто кому поставляет (А → В или В → А). Для выражения подобных отношений в множество дескрипторов должны быть включены служебные слова (прежде всего предлоги) и построена формализованная грамматика, превращающая это множество в некоторый формальный язык. В зависимости от мощности изобразительных средств такого языка можно в той или иной степени улучшить информационные характеристики АИС. Однако за такое улучшение приходится расплачиваться усложнением поиска, а следовательно, уменьшением производительности и увеличением стоимости системы.
6.3. Организация последовательных файлов
Последовательным файлом называется именованная линейно упорядоченная последовательность записей одного и того же типа. Именно в таком виде файл представляется прикладному программисту. Однако в зависимости от вида используемой памяти реальное физическое размещение в ней отдельных записей может сильно отличаться от подобного представления. При работе с файлами возникает необходимость как последовательного просмотра записей, так и прямой адресации записи по ее ключу.
Последовательный просмотр записей проще всего обеспечивается соответствующим (последовательным) их размещением в памяти. Так поступают, как правило, при использовании ЗУ с последовательным доступом (магнитных лент). В случае ЗУ других типов записи часто размещаются в другом порядке, определяемом прежде всего удобствами их прямой адресации. Для возможности перехода от очередной записи к следующей за ней пользуются встроенными в записях указателями. Наиболее быстрый поиск следующей записи происходит, если в качестве указателя используется истинный физический адрес ее начала. Однако при этом указатели становятся зависимыми от положения файла в памяти. При его перемещениях указатели надо менять. Более удобными в этом отношении являются относительные адреса, показывающие положение в ЗУ следующих по порядку записей по отношению к данным записям. Возможны и более сложные способы формирования указателей, обеспечивающие полную машинную независимость процедур последовательных просмотров файлов.
Заметим, что при порче какого-либо указателя часть записей может оказаться потерянной для программ последовательного сканирования файлов. Обеспечение проверки и восстановления искаженных или утерянных указателей возможно при введении обратных указателей (от данной записи — к предшествующей ей). Такое восстановление делается специальными программами обеспечения сохранности файлов.
Прямая адресация записей (по их ключам) выполняется различными типами процедур. В случае ЗУ с последовательным доступом прямая адресация так или иначе требует последовательного сканирования файла со сравнением ключа каждой очередной записи с заданным (для поиска) значением ключа. В ЗУ других типов могут использоваться более быстрые процедуры адресации. Если записи в ЗУ упорядочены по ключу, то можно использовать, например, блочный метод. При нем сначала просматриваются записи в начале крупных блоков записей с целью фиксации блока, в котором находится искомая запись. После нахождения нужного блока поиск в нем можно организовать либо последовательным сканированием, либо снова блочным способом (с менее крупными блоками). Подобный прием иерархического блочного поиска используется человеком при поиске нужного слова в энциклопедии (сначала фиксируется том, затем страница и, наконец, сканируется найденная страница).
Если в иерархическом блочном поиске на каждом шаге используются лишь два блока (равных с точностью до единицы длины), то приходим к наиболее быстрому (в классе блочных методов) методу дихотомического (или двоичного) поиска. При его применении количество просматриваемых записей при файле из записей имеет порядок .
Индексный метод адресации использует специальную таблицу, называемую индексом, которая соотносит различным значениям ключа адреса соответствующих записей или блоков таких записей. Если таким образом идентифицируется лишь адрес блока, а внутри блока поиск делается последовательным сканированием, то метод именуется индексно-последовательным.
Наконец, еще один способ использует те или иные алгоритмы для преобразования ключа в адрес. Эти алгоритмы могут использовать специальные свойства ключа. Например, если ключ принимает все значения от 1 до все записи имеют одинаковую длину ячеек ЗУ и помещаются в последовательные ячейки, начиная с -й, то адрес записи с ключом вычисляется по формуле .
Заметим, что подобный способ можно в принципе применять не только к числовым, но и к буквенным ключам, предварительно заменив буквы их цифровыми кодами. Однако при этом многим числовым значениям в диапазоне изменения ключа не будут соответствовать никакие используемые его значения. Поэтому простые формулы адресации типа только что рассмотренной дадут плохое заполнение памяти. Чтобы избежать такой ситуации, используется специальный прием, называемый перемешиванием (hashing). Его смысл заключается в подборе алгоритма, отображающего множество используемых значений ключа в множество адресов с достаточно плотным заполнением памяти (порядка 80 %). Перемешиванием этот прием называется потому, что используемые им алгоритмы располагают записи ЗУ в случайном порядке (а не в порядке их расположения в файле).
К сожалению, подыскать достаточно простой алгоритм, дающий не только плотное, но и взаимно однозначное отображение множества значений ключа в множество адресов, удается далеко не всегда. Поэтому может оказаться, что при перемешивании разным значениям ключа будет соответствовать один и тот же адрес. Чтобы выйти из затруднения, при перемешивании определяется адрес целого блока ячеек — так называемого пакета, в котором могут размещаться несколько записей. Если какой-либо пакет оказывается полностью заполненным, а в нем требуется поместить новые записи, то эти записи направляются в первый из свободных пакетов переполнения, адреса которых известны программе поиска.
Среди алгоритмов нахождения адреса пакета, в который следует поместить запись со значением ключа, равным , отметим один из наиболее простых и эффективных. Он основан на выборе числа , не имеющего малых делителей (желательно простого) и вместе с тем близкого к выбранному числу пакетов. Тогда адрес определяется как остаток от деления на . Если — число записей, размещаемых в одном пакете, а — общее число записей в файле, то для хорошего заполнения памяти должно соблюдаться условие .
При поиске записи по ключу поиск прежде всего производится в пакете, адрес которого вычисляется с помощью правила: есть остаток от деления на . Если записи с заданным значением ключа там не окажется, то производится последовательное сканирование пакетов переполнения. Подбирая должным образом параметры и , можно добиться того, что при достаточно хорошем заполнении памяти поиск большинства записей потребует лишь одного сканирования (без обращения к пакетам переполнения).
Рассмотрим еще некоторые особенности работы с файлами при размещении их в ЗУ различных типов.
6.3.1. Файлы на магнитных лентах
Как уже отмечалось выше, при адресации записей на магнитных лентах (МЛ) используется последовательное сканирование файла. Обмен между МЛ и оперативной памятью идет блоками (см. § 3.2), которые обычно содержат не одну, а несколько (иногда достаточно много) записей. Поиск записи в блоке, переданном в ОЗУ, может производиться как последовательным сканированием, так и описанными выше блочными методами. Актуализация файла на МЛ делается обычно достаточно большими порциями. Изменения накапливаются в специальном актуализационном файле и в соответствии с утвержденным расписанием переносятся в основной, файл, который при этом фактически переписывается заново.
6.3.2. Файлы на магнитных дисках
Наиболее распространенной формой организации файлов на магнитных дисках (МД) является индексно-последовательный метод. Если файл размещается на одном цилиндре (см. п. 3.3.3), то одна из дорожек отдается под индекс дорожек. Под область переполнения отводится обычно также одна дорожка. На остальных дорожках организуются блоки записей, упорядоченные по ключу: например, на первой дорожке помещаются записи со значениями ключа от 1 до 120, на второй — от 120 до 300 и т. д. На дорожке записи размещаются в произвольном порядке.
В индексе дорожек хранятся граничные (минимальные или максимальные) значения ключа для каждой дорожки с указателями на соответствующие дорожки. Имеется также указатель на область переполнения.
Если файл подвержен частым изменениям, то целесообразно при его начальном формировании не заполнять полностью дорожки. Поэтому, когда файл пополняется новыми записями, специальная программа, сверяясь с индексом, направляет его на соответствующую дорожку. И лишь при отсутствии свободных мест на дорожке запись направляется в область переполнения. При обращении к записи по ее ключу сначала идет ее поиск (после обращения к индексу) на основной дорожке. В случае отсутствия требуемой записи поиск продолжается в области переполнения. Поскольку все операции выполняются в пределах одного цилиндра, перемещения блока головок не требуется. Переключение же дорожек (в одном цилиндре) осуществляется с помощью электронных схем с большой скоростью.
Если файл не помещается на одном цилиндре, то он продолжается (обычно на соседние цилиндры) в пределах данного пакета дисков, который, будучи заполнен данными, носит обычно наименование тома. Заполнение цилиндров идет (как и в случае дорожек) в порядке роста (или убывания) ключа, по которому упорядочен файл. По аналогии с цилиндром в томе создается своя область переполнения и индекс цилиндров. Если файл выходит за пределы одного тома, то создается индекс томов, а в случае необходимости и еще одна дополнительная область переполнения.
Обращение к записям начинается со старшего индекса (с целью определения нужного тома) и продолжается далее по иерархии индексов, пока не будет найдена нужная дорожка. Поэтому указатели старших индексов адресуют следующие по старшинству индексы, и лишь самый младший индекс (индекс дорожек) адресует дорожки с записями. В случае, когда нужная запись на основной дорожке не найдена, происходит переход к сканированию областей переполнения в возрастающем порядке иерархии (сначала для цилиндра, затем для тома и, наконец, для множества томов).
Заметим, что в случае магнитных барабанов и дисков с фиксированными головками понятия тома и цилиндра совпадают. Томом называют также и магнитную ленту, заполненную информацией.
Актуализация файлов с индексно-последовательной организацией может производиться в истинном масштабе времени: при получении очередной новой записи (или изменении имеющейся) соответствующие коррективы вносятся в файл немедленно (обычно после окончания очередного цикла работы прикладных программ с файлом). При большой продолжительности времени существования файла, как и в случае файлов на магнитных лентах, могут производиться его периодические перестройки. Такая перестройка (выполняемая с помощью специальных программ) затрагивает, разумеется, не только сам файл, но и соответствующие ему индексы.
6.3.3. Файлы в ЗУ с произвольным доступом
Если размер файла позволяет разместить его в ЗУ с произвольным доступом, то он чаще всего организуется таким образом, чтобы была возможность прямой адресации записей по тому или иному ключу. Для этой цели может использоваться любой из описанных выше способов. Актуализация таких файлов производится, как правило, в истинном масштабе времени.
6.3.4. Файлы в ассоциативных ЗУ
Наиболее просто прямая адресация записей по ключу производится в ассоциативной памяти, которая специально приспособлена для этой цели. При использовании ассоциативных ЗУ нет необходимости прибегать к каким-либо алгоритмам преобразования ключа в адрес. Адресация (по шинам признака) производится непосредственно кодом значения ключа. До начала 80-х годов ассоциативная память для операций с файлами не получила сколько-нибудь широкого распространения. Однако успехи микроэлектроники делают такую перспективу в ближайшем будущем достаточно реальной.
6.4. Организация иерархических файлов
В большинстве приложений наряду с последовательными файлами приходится иметь дело с иерархическими файлами, в которых записи связаны в древовидные структуры, описанные в § 1.8. Заметим, что даже отдельная запись, как, например, кадровая анкета, может рассматриваться как иерархическая структура. Для этого достаточно найти атрибут, состоящий из более мелких элементов. В нашем случае таким атрибутом может служить дата рождения, разлагающаяся на три элемента: год, месяц, число.
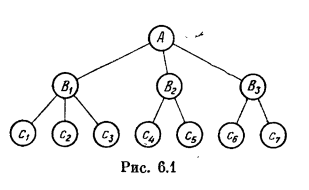
При размещении иерархического файла в ЗУ используется несколько разных способов. Одним из наиболее старых является последовательное размещение файла в виде так называемой левосписковой структуры. Ее смысл легко уяснить из следующего примера. Пусть необходимо разместить файл, изображенный на рис. 6.1. Тогда начинают с корня и идут по самой левой ветви, доходя, наконец, до листа. Затем слева направо проходят все листья, принадлежащие одному и тому же узлу . После этого Рис. 6.1 переходят к узлу и перечисляют его листья и т. д. В результате получают последовательность записей .
Следующий способ — использование множественных встроенных указателей. В нашем случае это означает, что в записи должны иметься указатели на записи , , , в записи — на записи , , и т. д. Помимо такой системы указателей на порожденные записи могут использоваться также указатели на исходные записи: в записях , , — на в записи — на и т. д. Наконец, наибольшее удобство при работе с иерархическими файлами достигается в случае дополнения систем указателей двух описанных типов указателям и на следующую подобную запись. В нашем случае это означает, что запись снабжается указателем на , — на ,— на , — на , — на и т. д.
В ряде случаев оказывается удобным вместо встроенных указателей использовать специальные справочники связей. В таком справочнике помещаются только идентификаторы записей, т. е. их основные ключи, а также все необходимые указатели. Благодаря тому, что справочник достаточно компактен, его (или некоторую достаточно большую его часть) можно поместить в оперативную память и осуществлять поиск с большой скоростью.
Таблица 6. 4.
| 1 | 1 | 1 | 0 | 0 | 0 | 0 | |
| 0 | 0 | 0 | 1 | 1 | 0 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 1 | 1 |
Помимо обычного способа задания связей в справочнике с помощью системы указателей иногда используются так называемые битовые отображения (или битовые таблицы). Смысл этого способа легко уяснить из конкретного представления битовым отображением связей между записями и иерархического файла (табл. 6.4), изображенного на рис. 6.1. Наличие связи от к характеризуется в таблице единицей на пересечении строки со столбцом . В случае же отсутствия связи на соответствующем пересечении стоит нуль. Битовые таблицы позволяют вести наиболее быстрый поиск связей в файле.
Заметим, что в случае необходимости прямого поиска записи по ее ключу используются те же самые механизмы, что и в случае последовательных файлов. Что ж е касается механизмов, описываемых в этом параграфе, то их назначение аналогично назначению последовательного сканирования записей в последовательных файлах.
6.5. Организация сетевых файлов
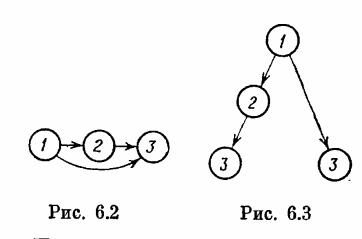
Иерархические файлы оказываются достаточными в большинстве приложений. Однако существуют важные приложения, в которых требуется обобщение этого понятия. Это имеет место, например, при организации управления на основе так называемых сетевых графиков (описываемых в последующих главах). Обобщение, о котором идет речь, снимает ограничение о наличии у каждой записи не более одной исходной записи и допускает произвольные связи между записями. Возникающие таким образом структуры называются сетевыми файлами. Простейший пример такого файла приведен на рис. 6.2.
При организации сетевых файлов используются уже описанные выше методы встроенных указателей, справочников и битовых отображений. Заметим также, что при введении избыточности за счет многократного повторения некоторых записей в базе данных сетевые структуры могут быть сведены к иерархическим. Такое сведение для файла, изображенного на рис. 6.2, показано на рис. 6.3. В рассматриваемом случае достаточно двукратного повторения записи 3.
Заметим, что в сетевых файлах довольно часто приходится именовать связь, а иногда и сопровождать дополнительным и данными, называемыми данными пересечения двух записей, соединяемых этой связью.
Простейший пример подобных именованных связей дают родственные связи между людьми (отец — сын, дядя — племянник и т. п.). С подобной ситуацией приходится иметь дело не только в сетевых, но и в некоторых иерархических файлах. Отношения типа «женаты», «разведены» и др. могут сопровождаться данными о времени установления соответствующего отношения.
6.6. Языки для описания данных
Графическое представление связей в базе данных сохраняет простоту и наглядность лишь в том случае, когда представляемые схемы несложны. В случае сложных схем стрелки могут скорее запутать, чем помочь. Кроме того, при вводе описаний в ЭВМ двумерное графическое представление все равно заменяется одномерным (ввиду линейной структуры ЗУ). Поэтому для описания данных создаются специальные языки. Простейшие из них встраиваются в алгоритмические языки. Примерами могут служить средства для описания данных в алголе-60 и коболе, рассмотренные в предыдущей главе. Заметим, что средствами кобола описываются иерархические структуры данных.
В ряде программных систем для банков данных, получивших достаточно широкое распространение (американская система IMS, советская Ока и др.), используются лишь иерархические структуры данных. Языки описания данных в этих системах строятся по тому же принципу, что и раздел описания данных в языке кобол.
Американская ассоциация по банкам данных Codasyl предложила другой язык, позволяющий описывать не только иерархические, но и многие сетевые структуры. Основой языка codasyl является понятие набора. Набор представляет собою именованное двухуровневое дерево. Его исходная запись (первый уровень) называется владельцем набора, а порожденные записи (второй уровень) — членами этого набора.
При описании данных, разумеется, приводятся не сами записи, а их типы, называемые также схемами. Примером двухуровневого набора может служить структура, в которой записью-владельцем является счет вкладчика сберкассы, а записями-членами — операции с этим счетом. В схемах записей указываются имена атрибутов, а также типы и форматы их значений (например, имя атрибута — фамилия, имя и отчество вкладчика, тип — алфавитный, формат — 30 букв). Описание схемы набора включает в себя имя набора, после чего объявляется и описывается сначала его владелец, а затем — члены.
Каждый из членов одного набора может быть объявлен владельцем другого набора. Продолжая этот процесс, можно, как нетрудно видеть, описать любую иерархическую структуру. Кроме того, не запрещаются и другие способы комбинаций наборов, благодаря чему создается возможность описывать непосредственно (без предварительного сведения их к иерархическим структурам) достаточно сложные сетевые структуры. Можно, например, создать два набора с одинаковыми членами, но разными владельцами, и т. п. В целом процесс описания схем данных с помощью наборов напоминает процесс оборки изделия из готовых конструктивных элементов.
Для указания способов вхождения в базу данных используется понятие так называемого сингулярного набора. Владельцем каждого такого набора объявляется система (имеется в виду операционная система ЭВМ, через которую прикладные программы взаимодействуют с базой данных). В отличие от других наборов, у которых схема набора и описываемый ею двухуровневый иерархический файл различны между собой (в схеме даны имена атрибутов, а в файле — их значения), для сингулярного набора схема и есть сам файл.
Смысл введения сингулярного набора состоит в следующем. Если прикладная программа хочет обратиться к какой-то записи, то для ее полного именования (с целью правильной адресации) следует использовать последовательность имен записей, начиная о члена одного из сингулярных наборов, которые связаны между собой отношением владелец — член. Например, если в базе данных записана информация об операциях по счетам вкладчиков не в одной, а в нескольких сберкассах, то простейшая схема структуры данных этой базы в принципе задается двумя наборами: в первом владельцем является сберкасса, а членом — вкладчик, во втором владелец — вкладчик, а член — операция. В языке codasyl к этим наборам нужно добавить набор, владельцем которого является система, а членом — сберкасса. Этим предопределяется тот факт, что прикладная программа, желая обратиться к какой-то конкретной записи о той или иной операции, должна именовать это обращение последовательностью имен сберкассы, вкладчика и, наконец, операции. В противном случае обращение может оказаться неоднозначным.
Описание базы в языке codasyl начинается с объявления имени схемы. Далее следует объявление имени области, за которым следуют описания записей, принадлежащих этой области. В одну область проектировщик базы данных помещает те записи, которые, по его мнению, будут часто использоваться совместно. Используя подобное разбиение по областям, программы, управляющие размещением данных в памяти, выполняют это размещение так, чтобы данные, принадлежащие к одной области, размещались в ЗУ близко друг к другу (в смысле времени перехода). Описание записей делается средствами, близкими к коболу.
К каждому типу записи (или ее элементу) может быть приписан так называемый замок секретности, в качестве которого могут употребляться специальные кодовые слова — пароль или специальная прикладная программа (составляемая владельцем информации). Такая программа определяет некоторую процедуру, разрешающую доступ к данным (например, серию вопросов, на которые программа, обращающаяся к данным, должна дать правильные ответы). При неправильных ответах (в простейшем случае — при незнании пароля) доступ к данным будет закрыт. Замками секретности могут снабжаться также и другие части описаний: схемы, области, наборы (члены набора) и др.
В конце описания описываются наборы (связи между данными). Для каждого набора указывается его имя и указание на характер размещения его членов (они могут помещаться в память либо в случайном порядке, либо упорядочиваться по ключу, указываемому в описании члена каждого типа). Далее указывается имя владельца набора, а затем — имена членов (с указанием ключа).
6.6.1. Общие требования к языкам описания данных
Язык описания данных в общем случае должен позволять описывать различные типы элементарных данных и их форматы, а также именовать их. То же самое должно иметь место и в отношении вводимых типов структур данных (запись, файл, область и др.).
Язык должен позволять специфицировать ключи и способ упорядочения данных по ключам. Он должен давать возможность определять любые отношения (связи) между записями (или другими группами данных), именовать эти отношения и, если необходимо, описывать характеризующие их данные. Кроме того, могут специфицироваться диапазоны возможных значений элементов данных и длины файлов. Язык также должен иметь возможность описывать замки секретности и другие средства защиты данных. В случае системных применений полезно также иметь средства для описания режимов актуализации данных.
Все указанные возможности (которыми не располагает целиком ни один из разработанных пока языков) относятся к описанию логических структур данных, т. е. тех структур, в виде которых данные представляются пользователю. Для описания физических структур данных, т. е. их реального расположения в памяти и методов доступа, нужны дополнительные средства, которые (в неформализованном виде) частично уже приводились выше в разделах, посвященных организации файлов.
6.7. Языки манипулирования данными (ЯМД)
Такие языки должны давать прикладному программисту машинно-независимые средства работы с базами данных. Они дополняют обычные языки программирования новыми операторами (макрокомандами). Частично подобная задача решается современными операционными системами. Поэтому системы интерпретации языков манипулирования данными в банках данных можно (и должно) рассматривать как расширение операционной системы. Хороший ЯМД должен иметь возможность использовать для общения с базой данных все стороны имеющихся средств описания данных. Разработанные к настоящему времени ЯМД в полной мере этому условию не удовлетворяют.
Приведем в качестве примера список операторов ЯМД codasyl, представляющий собой расширения средств манипулирования данными, которые встроены в кобол.
Оператор open (открыть) открывает (т. е. делает доступным прикладной программе) файл или набор, имя которого указывается после имени оператора. Поскольку открытие наборами файла влечет за собой приведение в готовность соответствующего механизма доступа к нему (описанного в предыдущей главе), а этот механизм может потребоваться другим программам, то после исчерпания потребности в открытом файле (наборе) он закрывается оператором close (закрыть).
Оператор find (найти) находит в базе данных запись, имя которой приводится в составе оператора, и делает ее текущей записью программы. Оператор get (взять) передает в рабочую область программы значения указанных элементов поименованной записи.
Оператор modify (модифицировать) изменяет значение определенных элементов данных поименованной записи. Новые значения данных берутся при этом из рабочей области программы. Оператор insert (вставить) вставляет в указанный набор codasyl'a (в качестве нового члена) запись из рабочей области программы. Обратный оператор remove (удалить) удаляет из набора поименованный экземпляр записи. Оператор store (заполнить) выполняет вставку в базу данных новой записи с организацией всех необходимых связей. В частности, таким образом может быть вставлена новая запись — владелец набора. Обратный оператор delete (устранить) удаляет из базы данных указанную запись и уничтожает все ее связи.
Оператор keep (удерживать) сохраняет настройку механизма доступа к записи с целью убыстрения повторных обращений. Обратный оператор free (освободить) отменяет действие оператора keep.
Наконец, с помощью оператора order (упорядочить) записи в поименованном файле или наборе упорядочиваются по указанному ключу в убывающей или возрастающей последовательности его значений.
6.8. Системы управления базами данных (СУБД)
Так именуется специальное (системное) программное обеспечение, которое позволяет прикладным программам работать с базами данных без знания конкретного способа размещения данных в памяти ЭВМ, т. е. физической структуры данных. Система управления при этом пользуется тремя видами описаний данных. С одной стороны — это описание логической структуры данных (сделанное прикладным программистом) в исполняемой прикладной программе. С другой стороны — это описание логической структуры базы данных, выполненное разработчиками этой базы (системными аналитиками и программистами). Наконец, третий вид описания — это описание физической структуры базы данных, также выполняемое системными аналитиками и программистами — разработчиками базы данных.
Заметим, что наряду с системными программистами в разработке баз данных должны, как правило, участвовать и системные аналитики, в задачу которых входит анализ предполагаемых способов использования проектируемых баз данных с целью оптимизации их логических и физических структур.
Программы, осуществляющие управление базой данных, обеспечивают в общем случае два интерфейса. Прежде всего это интерфейс между логической и физической структурами базы данных. Программы, обеспечивающие этот интерфейс, осуществляют преобразование логических имен данных в физические адреса, интерпретируют операторы язы ка манипулирования данными и осуществляют фактический обмен информацией между базой данных и рабочими областями прикладных программ. Последние две операции выполняются программным обеспечением базы данных совместно с операционной системой ЭВМ, на которой реализована эта база.
Второй интерфейс — это интерфейс между логической струной данных, описанной в прикладной программе, и логической структурой самой базы. В банках данных первого поколения эта задача решалась весьма просто, поскольку прикладным программистам разрешалось пользоваться лишь подсхемами схемы базы данных. В банках данных второго поколения прикладным программистам разрешается использовать произвольные, удобные для них логические структуры данных (предварительно описав их на принятом в системе языке описания данных). Разумеется, эти структуры могут использовать лишь те элементы данных, которые содержатся в базе данных. Однако форматы записей и связи между данными могут очень сильно отличаться от стандартов, принятых в базе данных.
Поскольку в этом случае прикладной программист в языке манипулирования данными использует не стандартные, а свои собственные представления о логических структурах данных, требуется еще один уровень интерпретации операторов НМД. Эти задачи полностью ложатся на специальное программное обеспечение соответствующего банка данных. Методы установления интерфейса между различными логическими структурами данных (составленных из одних и тех же элементов) требуют привлечения новых средств. Один из наиболее перспективных подходов к решению такой задачи дают так называемые реляционные структуры данных, о которых будет рассказано ниже.
Помимо уже описанных задач, на программное обеспечение (ПО) банков данных возлагаются и другие функции. Среди них отметим прежде всего задачи обеспечения секретности и сохранности данных. ПО банка данных выполняет процедуры проверки права на доступ к данным, объявленным по тем или иным причинам секретными. О сущности этих процедур уже говорилось выше.
Заметим, что использование в качестве замков секретности не просто паролей, а программ, составляемых самими пользователями, позволяет пользователям конструировать сколь угодно хитрые замки. Например, поскольку операционная система ведет учет текущего времени (дат, часов, минут и секунд), то пользователь может предусмотреть в программе систему паролей, меняющихся в зависимости от времени.
В целом, машинная (безбумажная) форма хранения информации может обеспечить гораздо более совершенные и надежные системы обеспечения секретности, чем традиционная бумажная.
Помимо защиты от неавторизованного доступа к секретным Данным важнейшее значение имеет защита любых (не обязательно секретных) данных от уничтожения или искажения. Подобная опасность может быть вызвана самыми различными причинами.
Во-первых, это случайные или преднамеренные физические воздействия (в основном с помощью электромагнитных полей) на носители (магнитные ленты, диски и др.), содержащие те или иные данные. Защита от таких воздействий предполагает специальные режимы хранения машинных носителей с данными, экранировку лентотек и дискотек и т. п. Кроме того, предусматривается необходимый уровень контрольного дублирования данных для возможности их восстановления на основных (рабочих) носителях в случае их уничтожения или порчи.
Второй возможный источник искажений данных — программы пользователей, которые могут по ошибке записать новые данные не в ту область памяти, в которую нужно. Чтобы избежать подобной опасности, вводится специальная система паролей, приводящаяся в действие только при записи. Не зная пароля, прикладная программа может читать (несекретные) данные, защищенные подобным паролем, но не может изменить их.
Процедуры защиты и восстановления данных приводятся в действие и контролируются специальным лицом — администратором банка данных, несущим всю полноту ответственности за сохранность находящейся в банке информации и соблюдение режима секретности. В число таких процедур, помимо уже описанных, могут включаться процедуры периодической инвентаризации содержимого банка с непременным соблюдением всех режимных требований. Для инвентаризационных и восстановительных процедур также создается специальное программное обеспечение.
Важное место в программном обеспечении банков данных занимают, как правило, процедуры актуализации (обновления) данных. В составе ПО банка такие процедуры могут отсутствовать лишь в том случае, когда используемая база данных является простой суммой баз пользователей. При таком положении задача актуализации базы данных возлагается на прикладные программы пользователей. В случае системных применений значительная часть базы данных (если не вся целиком) обеспечивается не зависящей от прикладных программ системой актуализации. Программное и административное обеспечение актуализации входит в этом случае в состав системы управления данных и попадает под юрисдикцию ее администратора.
Под административным обеспечением здесь понимаются специальные должностные инструкции для лиц, являющихся источниками актуализации, о порядке, сроках подачи и формах документирования актуализационной информации, а также о порядке ввода этой информации в систему. При больших размерах базы данных назначаются администраторы отдельных ее частей, несущие ответственность за сохранность подведомственных им частей, а также за своевременную и правильную их актуализацию.
Собственно обработка данных из баз данных осуществляется прикладными программами, составляемыми на алгоритмических языках. При этом для обеспечения взаимодействия прикладных программ и СУБД должны создаваться интерфейсы между соответствующими системами программирования и СУБД, на которые возлагаются функции по согласованию программной связи и связи по данным. Такие интерфейсы чаще создаются для систем программирования, ориентированных на обработку данных, таких, как кобол, PL-1 и др., и обычно включаются в СУБД.
6.9. Реляционные базы данных
Реляционный подход к описанию структур данных основывается на использовании для их описания язы ка предикатов (см. § 1-5), или, как в этом случае принято говорить, произвольных (-местных) отношений, причем отношений только между элементарными данными. Любое подобное отношение может быть представлено двумерной таблицей (табл. 6.5).
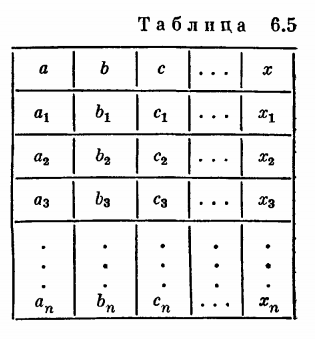
На этой таблице представлено отношение с именем над элементарными данными с именами . Каждая строка таблицы представляет собой набор значений этих данных, находящихся между собой в данном отношении (иными словами, отношение для них истинно). Строки таблицы принято называть кортежами, а столбцы — доменами (используется также термин атрибут). Если количество столбцов (или, что то же самое — Длина кортежей) равно , то говорят, что отношение имеет степень или является -местным (-арным) отношением.
Считая кортежи отдельными записями, легко представить заданное отношение (таблицу) в виде простейшего последовательного файла. Организация таких файлов в ЭВМ была подробно изложена в § 6.3.
Главная идея реляционного подхода состоит в том, чтобы представлять произвольные структуры данных в виде совокупностей описанных таблиц (отношений). Процесс такого представления (точнее, переход от других форм представления к описанному) называется нормализацией, а само представление — реляционной структурой. Если на отношения реляционной структуры не накладывается никаких ограничений, кроме отсутствия одинаковых строк в таблице, то говорят, что она представлена в первой нормальной форме.
Очевидным способом может быть проведена нормализация любого иерархического файла, записями которого являются элементарные данные. Для этого достаточно «размножить» узлы файла так, как это показано на рис. 6.4.
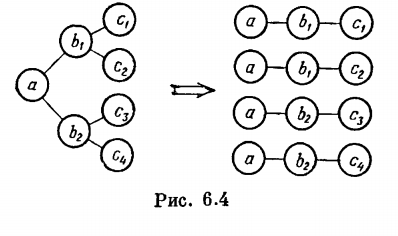
После такого размножения фактически уже получено представление файла в виде требуемой таблицы. Достаточно лишь именовать домены и присвоить таблице имя соответствующего файла.
Если записи сами представляют собой иерархические структуры, то тот же самый процесс «размножения» узлов можно применить и к ним. В результате, как легко видеть, файл будет приведен к виду плоской таблицы. В случае сетевых структур тем же самым приемом «размножения» узлов они приводятся сначала к иерархической, а затем и к реляционной (табличной) форме.
Приведенные приемы нормализации очень просты, но приводят к большой избыточности в логическом представлении данных, которая, однако, не означает избыточности хранения этих данных. Однако наибольшая неприятность при этом состоит в том, что актуализация таких отношений может привести к так называемым аномалиям манипулирования, когда происходит разрушение и/или потеря данных. Действительно, если в отношении, приведенном в табл. 6.6, исключить выделенную запись, то это приведет к потере информации об адресе учебного заведения КГУ, если в отношении нет больше записей с данным шифром учебного заведения. Чтобы не допустить возникновения аномалий, прибегают к декомпозиции отношений, о чем подробнее говорится ниже. Для рассмотренного примера отношение целесообразно разбить на два, как показано ниже (табл. 6.7 и 6.8).
Таблица 6.6.
| Ф.И. О. | Образование | Шифр законченного учебного заведения | Адресс учебного заведения |
| Иванов И. И. | высшее | КГУ | г. Киев |
К недостаткам можно отнести также и то, что результатом нормализации является отношение высокой степени, в то время, как на практике могут представлять особый интерес и даже требовать специального именования отношения меньшей степени[1]. Поэтом у процесс нормализации обычно продолжается дальше в направлении расщепления сложных (многоместных) отношений на более простые.
Таблица 6.7
| Ф. И. О. | Образование | Шифр учебного заведения |
| Иванов И. И. | Высшее | КГУ |
Таблица 6.8
| Шифр учебного заведения | Адресс учебного заведения |
| КГУ | Г. Киев |
6.9.1. Алгебра отношений
Огромным преимуществом реляционного представления структур данных является то, что на множестве отношений легко определяются различные операции, превращающие это множество в алгебру отношений (реляционную алгебру). Прежде всего можно, выделяя какую-либо часть доменов (столбцов) данного отношения, получить отношение меньшей степени. При выполнении этой операции, называемой проекцией, предполагается, что в получающейся таблице устраняются возможные повторения строк.
Операция объединения (соединения), обозначаемая звездочкой (*), позволяет «склеить» несколько отношений в одно истинное тогда и только тогда, когда истинны все объединяемые отношения. При этом помимо имен объединяемых отношений должно быть указано, какие домены из этих отношений нужно включить в результирующее отношение. Заметим, что при такой операции число строк может уменьшиться и даже свестись к нулю (что означает получение в результате пустого отношения). Например, при объединении отношения , задаваемого кортежами , и отношения с кортежами по всем трём доменам, которые мы обозначим через , возникнет отношение с единственным кортежем . Символически это может быть выражено формулой .
Возможны и другие операции над отношениями. Если в состав программного обеспечения реляционной базы данных включить программы, которые автоматизируют выполнение этих операций, то они могут осуществить отображение одной логической структуры данных в другую. При этом, разумеется, мы предполагаем, что обе структуры описаны в виде схем отношений (таблиц). Программы перевода производят заполнение таблиц второй структуры, используя таблицы первой структуры. Тем самым автоматизируется интерфейс между различными логическими структурами данных, т. е. решается задача, о которой говорилось в § 6.8.
На администрацию системы при этом ложится задача задания (в описании данных) формул реляционной алгебры, с помощью которых из отношений логической структуры базы данных получаются отношения структуры, используемой прикладным программистом. Более высокий уровень автоматизации интерфейса предполагает использование лишь описаний связываемых структур данных на специальном языке описания данных, расширенном с помощью так называемого исчисления отношений (реляционного исчисления). В этом случае система сама определяет пути реализации такого «описательного» отображения.
6.9.2. Исчисление отношений
В реляционном исчислении главным средством описания новых отношений исходной структуры является символическое обозначение вида . Оно означает отношение с именем , полученное в результате проекции кортежей, удовлетворяющих булевскому выражению , на домены , где — имя отношения (исходной структуры), — имя домена из этого отношения. Различают квантор существования (сокращение для слова «существует») и квантор всеобщности (сокращение для слов «для всякого»). Двоеточие () используется для сокращенного представления слов «такой, что». В качестве примера задания отношения в языке реляционного исчисления рассмотрим выражение
А (К. ФИО, К. зарплата): К. цех = 3 зарплата 150.
Оно задает таблицу (отношение) с именем с двумя доменами из таблицы (отношения) (кадры). Первый домен содержит фамилии, имена и отчества рабочих, второй — размер месячной зарплаты. При этом в таблицу включаются только рабочие третьего цеха с размером зарплаты, большей, чем 150 рублей в месяц.
6.9.3. Вторая и третья нормальные формы
Если в отношении какой-либо атрибут или группа атрибутов полностью определяют другой атрибут (или группу атрибутов) , то говорят, что функционально зависит от . Слова «полностью определяют» означают, что любому значению соответствует лишь одно, а не несколько значений . Атрибут (или группа атрибутов) называется полно зависимым от группы атрибутов , если функционально зависит только от всего множества , а не от какого-либо его собственного подмножества.
Назовем возможным ключом отношения атрибут или группу атрибутов, значения которых однозначно идентифицируют строку задающей отношение таблицы. Атрибут, входящий в состав какого-либо возможного ключа, будем называть основным (первичным).
Говорят, что отношение задано во второй нормальной форме, если оно находится в первой нормальной форме и каждый атрибут, не являющийся основным, полно зависит от любого возможного (вообще говоря, составного) ключа в этом отношении.
Если любой такой ключ является простым ключом и не зависит функционально от или — от , говорят о неполной транзитивной зависимости от .
Преобразование второй нормальной формы в третью нормальную форму состоит в расщеплении отношения на два отношения и с атрибутами и .
В качестве примера рассмотрим отношение с тремя атрибутами: номер работника, номер выполняемого им задания, расчетный срок выполнения задания. Здесь третий атрибут неполно транзитивно зависит от первого атрибута, поскольку один и тот же работник может выполнять несколько заданий. Поэтому после приведения отношения к третьей нормальной форме представляющая его таблица распадется на две. В первой таблице номеру работника соотносятся номера выполняемых им заданий, во второй — номеру задания соотносится расчетный срок его выполнения.
В программное обеспечение реляционных баз данных обычно включаются программы для автоматической нормализации. Значит, при разработке базы данных достаточно задать все необходимые атрибуты и отношения между ними в произвольной форме. ПО базы данных выполняет после этого приведение к третьей нормальной форме, обращаясь к разработчику лишь для согласования имен, возникающих в процессе нормализации новых отношений. Что же касается логической структуры базы данных, то наиболее удобно оказывается использовать для нее третью нормальную форму.
6.9.4. Проектирование реляционных баз данных
Проектирование реляционных баз данных основывается на трех принципах: эквивалентных преобразований схемы базы данных, уничтожения аномалий манипулирования данными и минимальной избыточности данных. В общем случае при проектировании ставится задача получения такой схемы базы данных, которая в определенном смысле эквивалентна и лучше исходной.
В настоящее время известны два подхода к определению понятия эквивалентности схем баз данных: эквивалентность по зависимостям и эквивалентность по данным. В определении эквивалентности по зависимостям требуется, чтобы схемы содержали одни и те же зависимости: если и — множества зависимостей двух схем, то эти схемы эквивалентны по зависимостям, при , где — замыкание по зависимостям. В определении эквивалентности по данным требуется, чтобы обе базы данных содержали одни и те же данные: две базы данных со схемами и соответственно содержат одни и те, же данные, если , где — операция естественного соединения отношений.
Как уже отмечалось, одной из целей проектирования реляционных баз данных является уничтожение аномалий манипулирования данными. Существенный вклад в решение этой проблемы дала теория нормализации баз данных. Введенная Коддом третья нормальная форма позволила существенно уменьшить (но не исключить полностью) аномалии манипулирования. При этом важно отметить, что третья нормальная форма сохраняет эквивалентность как по зависимостям, так и по данным. В теории нормализации рассмотрены и другие нормальные формы, в том числе полностью исключающие аномалии манипулирования, однако, каждая из них либо теряет эквивалентность по данным или зависимостям, либо допускает аномалии.
Как и в случае эквивалентности, можно дать два определения избыточности: избыточность по зависимостям и избыточность по данным. Система отношений с множеством зависимостей Г избыточна по зависимостям , если Система избыточна по данным отношения , если . Известно, что для любого отношения существует такая третья нормальная форма, которая не избыточна по функциональным зависимостям.
В связи с двумя подходами к определению эквивалентных преобразований схем баз данных существуют два метода проектирования схем: синтез и декомпозиция. Синтез предполагает сохранение эквивалентности по зависимости, а декомпозиция — по данным. В алгоритмах синтеза достижима только третья нормальная форма, в то время как в алгоритмах декомпозиции — любые. При синтезе нельзя получить такие отношения, в которых полностью снимались бы аномалии манипулирования, в то время как при декомпозиции можно. В алгоритмах синтеза можно достичь минимальной избыточности по функциональным зависимостям, а в алгоритмах декомпозиции — по данным.
Отсутствие единого решения проблемы проектирования реляционных баз данных в рассмотренной постановке приводит к необходимости на практике определять и отслеживать возможные нарушения в процессе ведения и преобразования баз данных с целью их предотвращения.
6.9.5. Преимущества и недостатки реляционных структур
Помимо уже разобранного выше преимущества, заключающегося в возможности для различных прикладных программ использовать различные представления логической структуры данных, реляционные структуры обладают и рядом других преимуществ. Это, во-первых, простота понимания и работы с базой (особенно для не очень опытных пользователей), поскольку большинство людей имеет практику работы с двумерными таблицами. Следует особо подчеркнуть, что графическое представление структур данных выглядит ясным и наглядным лишь для структур малой сложности: при большой сложности структур представление их в виде таблиц обеспечивает большую ясность и точность.
Наряду с простотой представления данных, работа с реляционными базами данных поддерживается языками манипулирования высокого уровня (уровня исчислений), избавляющими пользователя от необходимости программирования поисковых процедур на базах данных. Для этого достаточно правильно указать в запросе, что необходимо найти, а не как найти. Этим достигается полное исключение необходимости прикладного программирования поисковых процедур при работе с базами данных.
Во-вторых, реляционную базу проще развивать и дополнять. Процедуры актуализации также, как правило, упрощаются. В-третьих, упрощается контроль секретности — секретные части отношений всегда могут быть выделены и изолированы от остальных (несекретных) частей. В-четвертых, упрощается физическая организация данных и ее интерфейс с логической структурой, благодаря чему банк данных легче адаптируется к возможным изменениям его технической базы.
Пятое преимущество состоит в том, что в реляционной структуре естественным образом выражаются отношения любой степени, а не только бинарные отношения, как это имеет место в случае иерархических и сетевых структур. Это преимущество становится сразу ощутимым даже в том случае, когда в структуре данных требуется выразить, например, множественное отношение, которое выделяет из списка людей отдельные семьи или какие-либо другие коллективы. Его задание возможно и в иерархических (а тем более сетевых) структурах, однако оно требует введения дополнительных записей и соответствующих ссылок.
Наконец, одно из важнейших преимуществ реляционных структур состоит в том, что отношения являются строго определенным математическим понятием и поэтому могут служить объектом строгой математической теории. Сюда же относится и уже описанная выше возможность введения алгебраических операций над отношениями, что придает реляционным структурам особую гибкость и возможность относительно простой адаптации к самым разнообразным требованиям.
К числу недостатков реляционных структур можно отнести большую сложность программного обеспечения логических интерфейсов, особенно при использовании реляционного исчисления. Определенный недостаток состоит также и в некоторой избыточности двумерных таблиц по сравнению с иерархическими и особенно сетевыми структурами. Эта избыточность наглядно иллюстрируется на рис. 6.4. Правда, в процессе нормализации расщепление отношений может заметно уменьшить избыточность представления и тем самым улучшить использование памяти.
6.10. Целосность баз данных
Выше (в § 6.8) мы уже познакомились с понятием сохранности базы данных. Понятие целостности представляет собой дальнейшее развитие этого понятия. Дело в том, что в системных применениях база данных, как правило, описывает некоторый реальный объект (или группу объектов). Иными словами, базы данных в этом случае выступают в качестве информационных моделей реальных объектов. Объекты же в большинстве случаев являются не статическими, а динамическими. Иными словами, они, а следовательно, и описывающие их данные меняются с течением времени. Отслеживание этих изменений в базе данных составляет сущность процесса ее актуализации, о чем уже не раз говорилось выше.
Если режимы актуализации различных частей базы данных не взаимоувязаны в единую систему, может возникнуть ситуация, когда данные, описывающие реальный объект, относятся к разным моментам времени. Иногда в этом может не быть никакой особой беды. Однако во многих случаях это ведет к серьезным искажениям и даже к появлению информационных моделей объектов, которые в действительности просто не могут существовать.
Простейший случай искажения возникает, например, при изменении стажа, разряда или должности. Если соответствующее изменение имело место и даже внесено в кадровый файл, но не внесено в файл, которым пользуется бухгалтерия при начислении зарплаты, то может возникнуть случай неправильного начисления зарплаты.
Более сложный пример дает практика автоматизированного проектирования в диалоговом режиме со многими проектантами, работающими на общей информационной базе. Предположим, что в процессе проектирования, скажем завода, один проектант переместил в определенное место какую-то единицу оборудования, а другой проектант еще не убрал с этого места «свое» оборудование. В этом случае база данных в соответствующий момент времени внутренне противоречива, ибо представляет объект, который в действительности не может существовать.
В обоих приведенных примерах нарушается целостность базы данных. Не вдаваясь далее в детализацию этого понятия, заметим, что наиболее полное понятие целостности базы данных основывается на глубоком, содержательном знании природы отображаемого ею объекта. Поэтому в общем случае задача автоматического контроля целостности базы данных и, тем более, восстановления целостности после ее случайной утери связана с задачей создания искусственного интеллекта и пока еще далека от полного решения.
Сказанное, разумеется, не исключает наличия автоматического контроля и исправления простых нарушений целостности баз данных того типа, который приведен в первом из двух рассмотренных выше примеров. В случае, когда для автоматического контроля и исправления некоторых нарушений целостности базы данных используются элементы содержательного знания об описываемом ею объекте, мы будем говорить о наличии элементов «интеллектуальности» этой базы данных (точнее — об интеллектуальности ее программного обеспечения).
6.11. Телекоммуникационные методы доступа
При работе с базами данных или с отдельными файлами с удаленных терминалов, помимо традиционных задач организации доступа, возникают многие дополнительные задачи. Необходимо организовать управление передачей, приемом и анализом сообщений, циркулирующих между ЭВМ и терминалами, проверять доступность и занятость не только терминалов, но и линий связи и т. д. Программы, обеспечивающие телекоммуникационный доступ организуют опрос терминалов о наличии у них сообщений для передачи и определяют порядок такой передачи. В случае режима соперничества, когда готовые для передачи терминалы борются за монопольное обладание линией связи, программы теледоступа следят за тем, чтобы не оставлять в течение сколько-нибудь длительного времени те или иные терминалы необслуженными.
Методы теледоступа могут использовать ЭВМ для коммутации сообщений, которыми обмениваются друг с другом удаленные терминалы. Они обычно также дают возможность дистанционного управления вводом заданий (программы ДУВЗ), так что с удаленных терминалов оказывается возможным решать большие задачи, программы и данные для которых были заранее предоставлены в распоряжение ЭВМ.
Методы теледоступа, обеспечиваемые стандартными ОС, предназначены в основном для позадачного подхода. При использовании баз данных дополнительно возникает задача установления интерфейса между СУБД и программами, обеспечивающими теледоступ. Задача состоит в организации так называемых транзакций, т. е. единичных актов взаимодействия в системе «база данных — передача данных» (БД — ПД), выполняемых по запросам удаленных пользователей. Необходимость обрабатывать поток запросов в реальном масштабе времени отличает данную ситуацию от обычной ситуации обеспечения интерфейса между базой данных и прикладными программами, которые работают в пакетном режиме (и потому могут спокойно ждать своей очереди). Следует особо подчеркнуть, что различные транзакции могут обслуживаться различными прикладными программами, работой которых также приходится управлять в реальном масштабе времени.
Подобный системный теледоступ позволяет создавать информационно-справочные системы (с удаленными и близкими терминалами), работающие в реальном масштабе времени, осуществлять быструю коммутацию сообщений между терминалами и др. Для ЕС ЭВМ функции системного теледоступа осуществляет программный комплекс Кама, работающий совместно с ОС ЕС и СУБД Ока.
6.12. Первичные и вторичные файлы в базах данных
При выборе форм представления файлов в базах данных возникает естественное противоречие между простотой и скоростью их актуализации, с одной стороны, и простотой и быстродействием их интерфейса с прикладными программами — с другой. Простота актуализации файла требует, чтобы структура его записей соответствовала принятым формам первичного учета. Например, записи в кадровом файле должны в свете этого требования содержать все атрибуты, принятые в утвержденной форме личного листка по учету кадров. В файле, описывающем оборудование, записи должны отражать принятые формы паспорта на отдельные единицы оборудования и т. д. Подобные файлы, подогнанные к задачам первичного учета, мы будем называть первичными файлами. При полноте учета первичные файлы составляют полную информационную модель характеризуемого ими объекта.
В то же время различные прикладные программы могут пользоваться только небольшой частью данных, содержащихся в том или ином конкретном первичном файле. Например, программе для начисления зарплаты сотрудникам не нужно большинство атрибутов кадровых анкет. То же самое можно сказать о программе планирования сменных заданий (доводимых до каждого рабочего) и др. Разумеется, СУБД могут снабжать прикладные программы данными непосредственно из первичных файлов. Ясно, однако, что при этом каналы обмена ВЗУ с ОЗУ будут загружены передачей большого числа лишних данных, потребуется неоправданный расход ячеек ОЗУ под буферы, снизится быстродействие интерфейса.
Поэтому в базах данных наряду с первичными файлами часто целесообразно иметь вторичные файлы, формы записей которых, а также способ упорядочения записей в файле ориентированы не на первичный учет, а на прикладные программы. Например, для задач планирования сменных заданий записи вторичного кадрового массива должны кроме учетного номера и имени рабочего содержать лишь данные о его квалификации и, возможно, стаже работы. При этом порядок следования записей в файле должен отражать принятую организационную структуру, т. е. распределение рабочих по цехам, участкам, бригадам и пр. С таким файлом задачи планирования будут решаться гораздо эффективнее как с точки зрения скорости работы, так и с точки зрения расходования ресурсов ЭВМ (прежде всего памяти и каналов).
Разумеется, вторичные файлы можно включить в базу данных, полностью уравняв их в правах (т. е. в организации процесса актуализации и интерфейса с прикладными программами) с первичными файлами. Однако на практике в большинстве случаев оказывается удобным поступать иным способом. Суть его состоит в том, что первичные файлы объединяются в особую (первичную) базу данных. Актуализация этих файлов приводится в соответствие с процедурами первичного учета в системе. В идеале такая актуализация ведется в истинном масштабе времени. Иными словами, изменения, поступающие с рабочих мест первичного учета, сразу же вносятся в соответствующие первичные файлы. На практике, разумеется, обычно довольствуются компромиссным решением: поступающие изменения накапливаются в специальных буферах и по мере их наполнения разносятся но соответствующим (первичным) файлам. Процесс «разнесения» поступивших изменений по файлам может регулироваться либо жестко (в установленное время), либо в зависимости от числа поступивших изменений. Система актуализации первичной базы данных обеспечивает тем самым главное ее назначение — быть информационным портретом (с той или иной разумной задержкой во времени) характеризуемого этой базой реального объекта.
Вторичные файлы могут существовать в виде статических (постоянно существующих) и динамических (возникающих лишь на нужный период времени) файлов. Процесс актуализации статических файлов и создания динамических файлов управляется не динамикой процессов первичного учета, а динамикой выхода «на счет» (исполнение) работающих с этими файлами прикладных программ. При этом используется то обстоятельство, что в большинстве системных применений ЭВМ выход на счет прикладных программ представляет собой не полностью случайный, а в определенной мере детерминированный, упорядоченный процесс. Закономерности этого процесса используются специализированной частью операционной системы, расширяющей систему управления заданиями в обычных ОС (рассчитанных на случайный лоток заданий). Результатом такого использования является заблаговременная подготовка (актуализация или создание заново) к нужному моменту необходимых вторичных файлов. Подобная специализированная ОС занимает промежуточное положение между обычными (пакетными) ОС и ОС реального времени.
Тем самым вторичные файлы как бы выделяются в особую (вторичную) базу данных, отличающуюся от первичной базы данных прежде всего способом организации процесса актуализации[2]. При этом первичные файлы используются в качестве своеобразных эталонов, по которым выверяются (или создаются заново) вторичные файлы. Так что программы актуализации вторичной базы данных могут строиться с помощью СУБД первичной базы, дополненной в случае необходимости программами «урезания» и переупорядочивания (сортировки). Ситуация здесь в какой-то мере напоминает организацию измерений на производстве: непосредственно для измерений употребляются рабочие приборы и инструменты, для контроля и настройки которых служит специальная эталонная аппаратура.
Способ ведения вторичных файлов (статический или динамический) определяется конкретными обстоятельствами. Часто обновляемые, но редко используемые вторичные файлы целесообразно иметь в динамическом виде, редко же обновляемые, но часто используемые — в статическом виде. Выбор одного из этих способов осуществляется обычно в результате моделирования проектируемой системы обработки данных.
Кроме того, в процессе работы системы, использующей банк данных, можно осуществлять те или иные процедуры статистических оценок частоты обращения к различным элементам данных. Полученные оценки используются для оперативной перестройки вторичной базы данных с целью повышения эффективности системы, использующей эту базу.
Практика работы современных информационно-справочных систем и систем оперативной обработки данных (в частности, автоматизированных систем управления) показывает, что обычно более 80% запросов относятся менее чем к 20% данных, находящихся в первичной базе данных.
6. 13. Распределенные базы данных
До сих пор рассматривались базы данных и СУБД, размещаемые и работающие на одной ЭВМ. Такие базы данных и СУБД называют локальными. Практически все чаще возникает необходимость в решении задач с распределенными базами данных, т. е. таких задач, для которых данные размещены по месту своего возникновения или наиболее эффективного использования, на ЭВМ, удаленных друг от друга на большие расстояния. При этом предполагается, что на каждой из ЭВМ данные управляются своими локальными СУБД.
Основу для решения таких задач составляют сети передачи данных, позволяющие соединять по каналам связи различные ЭВМ, обеспечивать техническую и программную поддержку обмена данными между ними, образуя тем самым сеть ЭВМ.
Обработка распределенных данных обычно строится так, что функции по выдаче в сеть транзакций на обмен данными с локализацией нужной ЭВМ сети и локальных баз данных возлагаются на обрабатывающую программу. Это, с одной стороны, значительно усложняет процесс прикладного программирования и, с другой — делает прикладные программы зависимыми от локализации данных в сети. С целью устранения этих недостатков при работе с распределенными данными создаются системы управления распределенными базами данных (СУРБД). Они строятся таким образом, чтобы максимально обеспечить соблюдение принципа независимости прикладных программ от локализации данных в сети, при котором логическое представление распределенной базы данных и манипулирование данными для прикладной программы ничем не отличаются от соответствующего локального варианта базы. Такие СУРБД оснащены каталогами, в которых хранятся структура сети, информация о локальных СУРБД и базах данных, а также программным обеспечением, которое на основе этой информации управляет взаимодействием прикладной программы и конкретной локальной базой данных сети.
Сложность управления распределенными базами данных ва многом зависит от того, поддерживаются ли они однотипными локальными СУРБД, взаимодействие между которыми осуществляется просто, так как для этого используется один общий язык. Если же, например, часть распределенной базы данных находится под управлением СУРБД сетевого типа, а другая — под Управлением СУРБД иерархического типа, то вопрос управления такой распределенной базой существенно усложняется. Один из путей разрешения возникающей сложности состоит в использовании некоторой промежуточной интерфейсной СУРБД (чаще всего реляционного типа), через которую на основе соответствующих отображений обеспечивается интерфейс между СУРБД.
Этот недостаток иногда оборачивается и преимуществом, поскольку одними лишь бинарными отношениями, используемыми иерархическими и сетевыми структурами, нельзя выразить всех требуемых отношений. ↩︎
Создание динамических файлов можно трактовать как частный случай актуализации, когда актуализируемый файл в начале процесса актуализации был пуст. ↩︎